
Hello World.
LiSMOtechの久津間です。
前回からPythonを使ったトピックを記載していますが、
今回はSeleniumライブラリを使ったブラウザの自動化について記載していきます。
Seleniumを使えば、普段ルーティンで行っている業務ももしかしたらSeleniumライブラリで全て自動化できてしまうかもしれません!
非常に便利なライブラリなので知らなかった方はご自身の環境で是非試してみてください!
SeleniumはWeb ブラウザの操作を自動化するためのフレームワークです。
Seleniumパッケージは、PythonからWebブラウザのUIテストを自動化する目的で開発されています。
テスト以外にもタスクの自動化や Web サイトのクローリングなど様々な用途で利用されています。
参考:https://pypi.org/project/selenium/
pythonではいくつかのスクレイピングライブラリがあるので、ここではそれぞれ特徴を記載しておきます。
Seleniumは最も代表的なライブラリで情報が入手しやすいライブラリです。
WEBアプリケーションの自動テストツールとして開発されたもので、ブラウザのWebDriver APIを経由して、ブラウザを外部から操作することでスクレイピングすることができます。
Beautiful SoupはHTMLやXMLからデータを抽出するための非常に人気のあるライブラリです。
シンプルなAPIを提供し、HTMLパーサーとして使用されます。
WEBスクレイピングにおいて頻繁に利用されるライブラリの1つです。アクセス方法が簡潔でわかりやすく、初心者でも扱いやすいです。
PuppeteerはGoogleによって開発されたNode.jsのライブラリで、Headless Chrome(またはChromium)を操作してブラウザの自動化やWEBスクレイピングを行うためのツールです。
JavaScriptの実行や動的なコンテンツの取得が必要なWEBスクレイピングやブラウザの自動化タスクにおいて非常に強力なツールといえます。
先ずはseleniumのインストールを行います。
ターミナルを開いて以下のコマンドを実行してください。
pip install selenium
chromeブラウザのバージョンを確認します。
確認方法はブラウザを開き、「ヘルプ」→「Google Chrome について」から確認することができます。
HomeBrewを使ってChromeDriverをインストールします。
※HomeBrewがインストールされていない場合、公式を参照してインストールする必要があります。
brew install chromedriver
無事に前準備が完了してインストールができれば後はseleniumを使ってWEBの操作を行ってみます。
先ずは最低限のコードでGoogle Chromeを起動します。
以下のコードを記載して保存します。
selenium_test.py
from selenium import webdriver
driver = webdriver.Chrome()
# Googleを開く
driver.get("https://www.google.co.jp/")
ターミナルから保存した.pyを実行してみます。
無事にGoogle chromeが表示されました!
続いて、弊社のサイトをGoogle窓から自動で検索するようにします。
開発者モード(検証)を開いて該当のテキストエリアのXpathを取得します。
該当のテキストエリアを選択し、「右クリック」⇨「Copy」⇨「Copy full XPath」と行います。
※XPath (XML Path Language)とは、ツリー構造となっているXML/HTMLドキュメントからの要素や属性値などを指定するための簡潔な構文(言語)
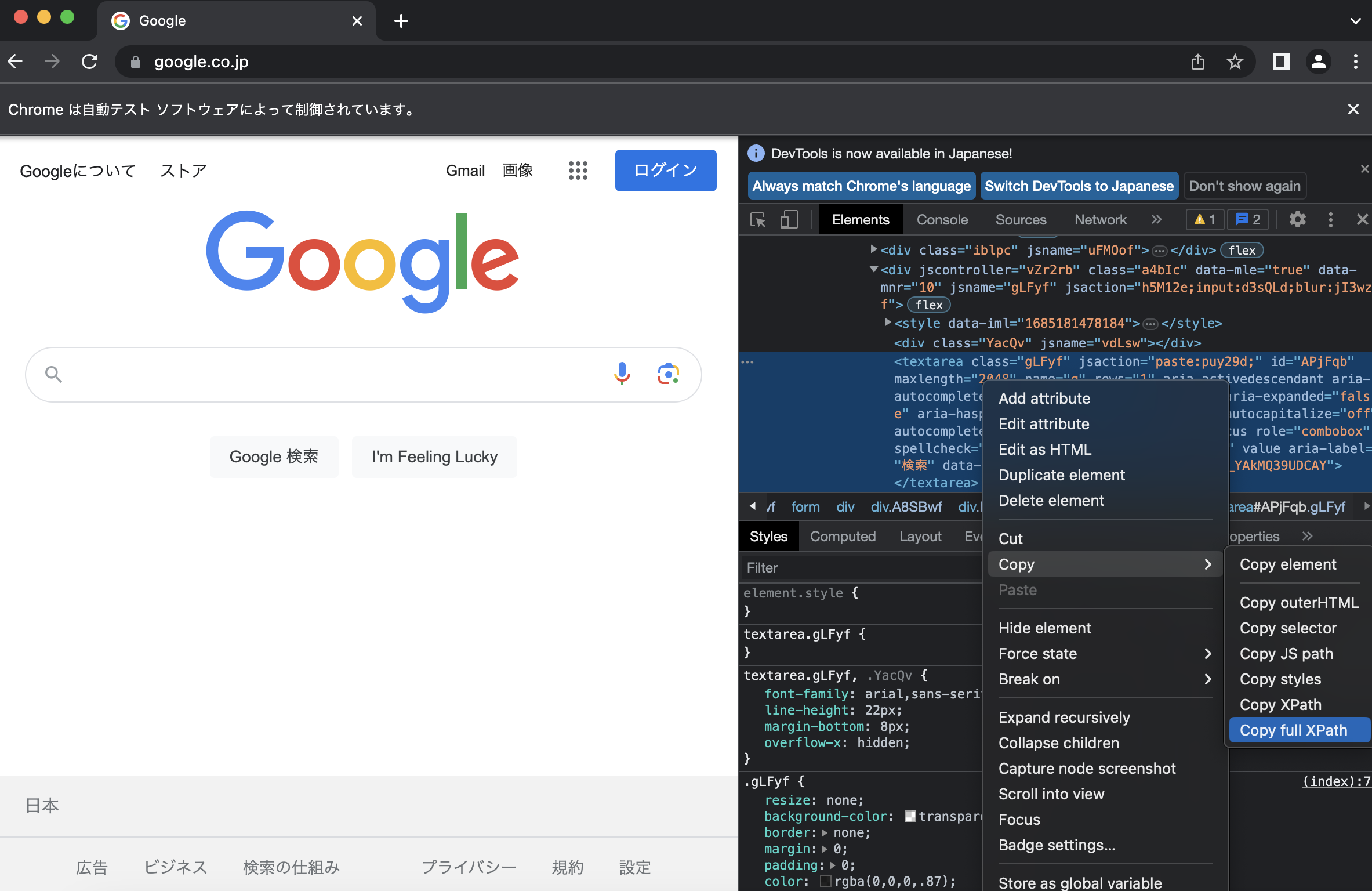
XPathのコピーが出来たらコードを以下のように変更していきます。
※検索ボタンのXPathも取得する必要があります。
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
import time
# Googleを開く
driver.get("https://www.google.co.jp/")
# 検索エリアを取得
element = driver.find_element(By.XPATH, "/html/body/div[1]/div[3]/form/div[1]/div[1]/div[1]/div/div[2]/textarea")
# キーワードを入力
element.send_keys("NEXTGATE LiSMOtech株式会社")
# 検索ボタンを取得
element = driver.find_element(By.XPATH, "/html/body/div[1]/div[3]/form/div[1]/div[1]/div[4]/center/input[1]")
# クリックイベント
element.click()
time.sleep(2)それではファイルを保存して実行してみます。
検索エリアに文字列が入り、検索が自動化できました!!!
WEBの自動化、いかがだったでしょうか!
今回は基本的なseleniumを使ったWEBの自動化を実践してみましたが、この他にもIDやCLASSなどを取得して操作することも可能です!
ご自身で試行錯誤しながら、日々のルーティン作業を効率化してみてください!
ともに考え、寄り添う。プロのデザインチームが即参戦。
販促ツールや一貫したデザインによるブランド構築などビジネスの成長をデザインの力で促進します。

NEXTGATE LiSMOtech株式会社は千葉県のクリエイティブカンパニーの企業です。
WEB制作をはじめ、紙媒体のデザイン、事業の販促物・広告等のクリエイティブ全般で事業の成功を支援させていただいてます。ご質問、お見積りなどお気軽にお問い合わせください。



NEXTGATE LiSMOtechでは中小企業を中心にブランディング・WEBマーケティングを活用したWEB戦略を提供しています。
企業課題・問題に関するご相談、WEBサイト制作やグラフィックデザイン制作のクリエイティブに関するご相談やご質問、お見積りなどお気軽にお問い合わせください。
平日10:00〜19:00
© NEXTGATE LiSMOtech All rights reserved




